Cloudflare Global Outage 討論
一篇好的公關技術文可以看出什麼端倪?
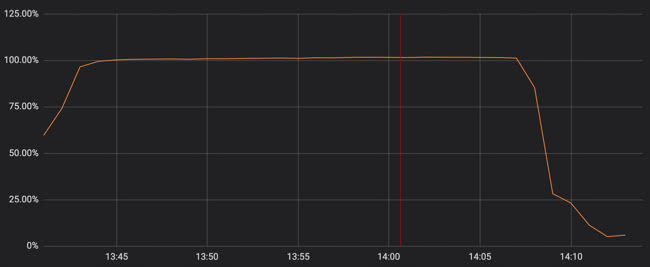
前陣子 Cloudflare global outage 導致許多服務突發性異常,7/12 號時 Cloudflare 針對此次意外釋出了一篇文章, 其中清楚的解釋整件事的來龍去脈。內容部分就不多提,有興趣的人建議一定要看。
針對文章個人覺得幾點特別值得注意:
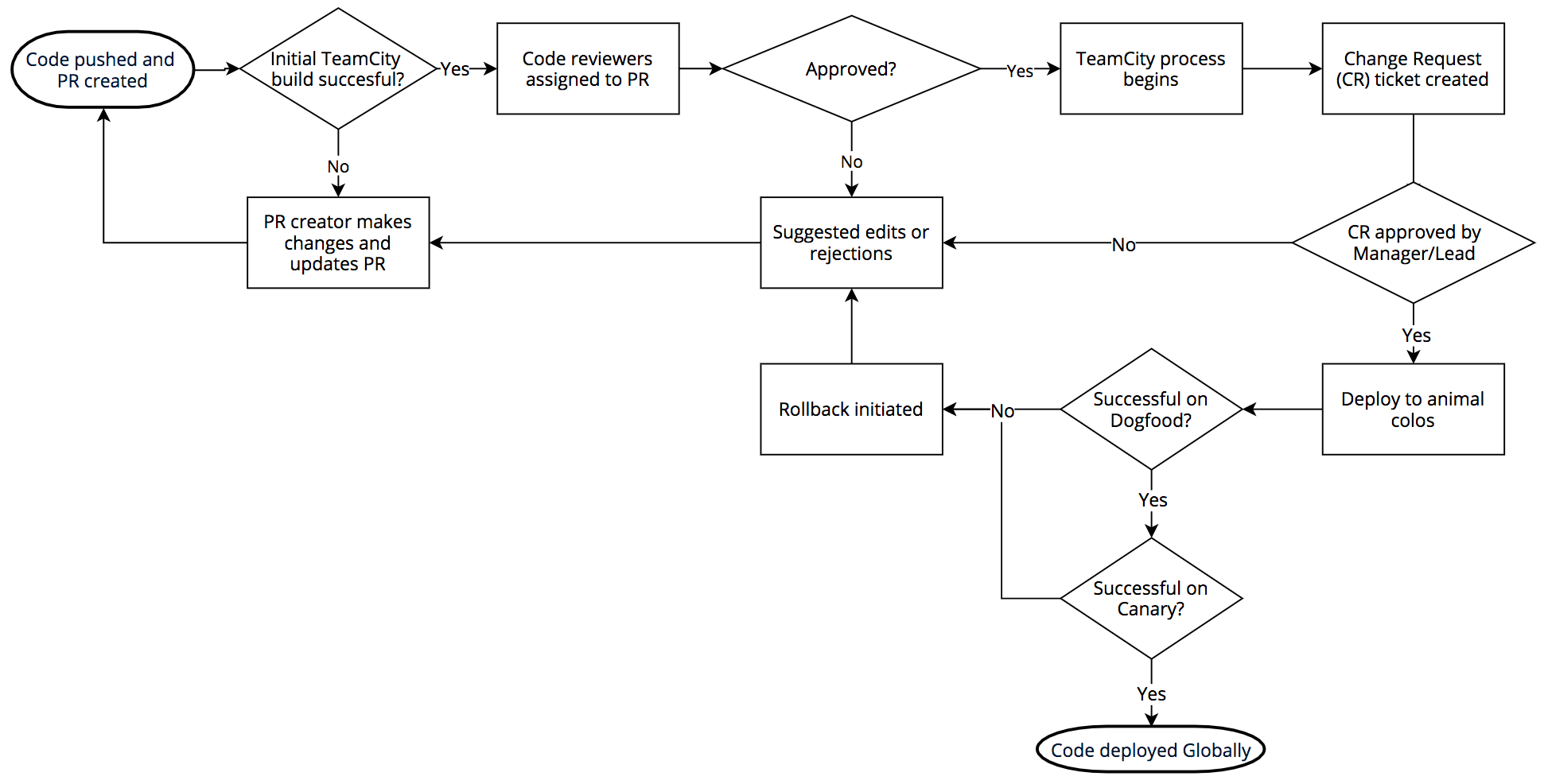
一般比較少見大型公司完整說明內部的 CI/CD 流程,透過這篇文章能一窺出其內部針對產品上線、測試、驗證的流程,以及發生回滾 (rollback) 除錯的概略圖。
自家服務斷線連帶影響到其安全存取服務,文章有點出針對這部分的訓練/經驗不足。跟 Gitlab 備份機制沒仔細驗證,出意外時才發現無法復原。很多時候不怕一萬只怕萬一。
文內有提供元兇的真面目,並且透過動畫清楚解釋該 regular expression 是如何造成 CPU exhaustion。並且清楚列出他們改變了什麼,避免未來再度發生類似意外。
# Original regular expression
(?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
# Critical part
.*(?:.*=.*)
# Which can be reduced to
.*.*=.*
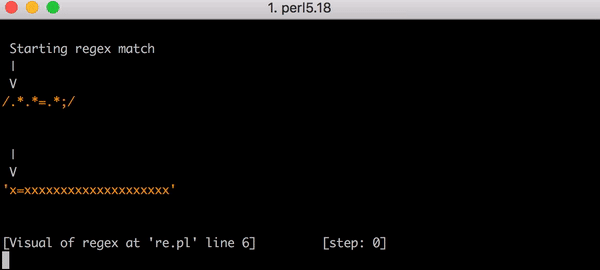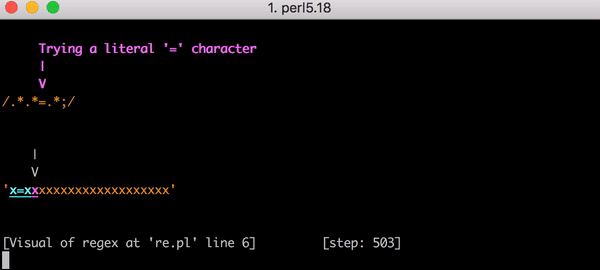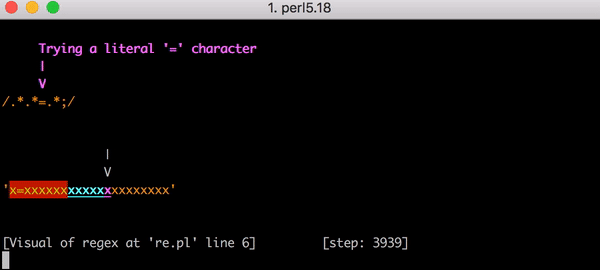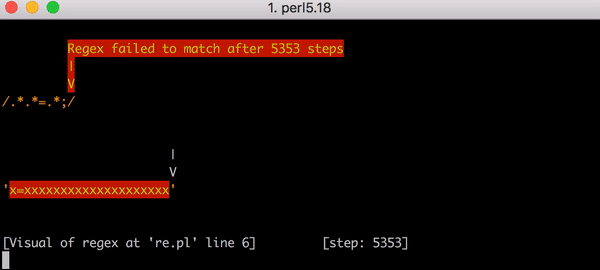
(關於 regular expression backtracking 可以看這篇 StackOverflow 說明)
雖然意外發生並非好事,但作為一篇公關技術文章,其中呈現他們如何快速應對此次意外,亦可從部署步驟中隱約透露他們做了哪些努力來盡力保護客戶免受惡意攻擊,相信能再度贏回客戶信心才是。(Gitlab 與 Github 發生意外時也有釋出相關文章,請參考下面連結)
- Cloudflare outage: https://blog.cloudflare.com/details-of-the-cloudflare-outage-on-july-2-2019/
- Gitlab outage: https://gitlab.com/gitlab-com/gl-infra/infrastructure/issues/4380
- Github incident: https://github.blog/2018-10-30-oct21-post-incident-analysis/
文章內容的轉載、重製、發佈,請註明出處: https://tachingchen.com/tw/
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email